
Webスクレイピングとは、Webサイトの情報を自動的に収集する技術でして、スクレイピングを得意とするのがPythonというプログラム言語です。
『シゴトがはかどる Python自動処理の教科書』では、Pythonを使って自動化できるネタがいくつか紹介されており、もちろんスクレイピングについても取り上げられています。
今回はこの本の内容を参考にしながら、Webサイトの記事一覧から各ページの情報を取得するスクレイピングのプログラムを作成します。
プログラムの内容
こちらがサンプルのデータです。Pythonがインストールされている環境で実行できます。
スクレイピングの対象は僕が作ったサイトを使います(サイトは閉鎖しちゃっているのでスクショでイメージしてください)

トップページに記事の一覧が「歴史散歩」と「歴史学入門」の2つあります。そのうち「歴史散歩」の方だけの記事タイトルとURLを取得します。
<div class="entry-list">
<h3>歴史散歩</h3>
<div class="post-date">2021年3月24日 投稿</div>
<h4><a href="https://yamashina.iehohs.com/narakaidou/">奈良街道から随心院まで歴史散歩</a></h4>
<div class="shiseki-tag"><a href="https://yamashina.iehohs.com/tag/zuishinin/" rel="tag">随心院</a></div>
<div class="excerpt"><p>今回は蓮如上人ゆかりの地である南殿光照寺の近くにある若宮八幡宮から奈良街道を進み、大宅一里塚まで下り、随心院を目指して歴史散歩をします。 若宮八幡宮 若宮八幡宮には2基の宝篋印塔があり、大津皇子と粟津王の供養塔と伝えられ […]</p>
</div>HTMLの一部抜粋です。記事の一覧は「.entry-list」というクラス名のdivタグで囲まれており、記事タイトルはh4タグが使用されています。
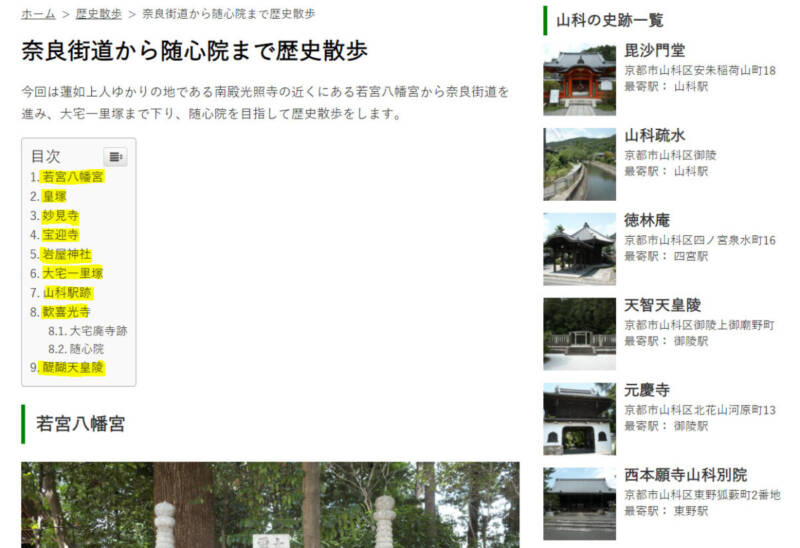
取得したURLからさらに各記事のページの情報も取得します。
<div class="entry-content">
<p>今回は蓮如上人ゆかりの地である南殿光照寺の近くにある若宮八幡宮から奈良街道を進み、大宅一里塚まで下り、随心院を目指して歴史散歩をします。</p>
<h2><span class="ez-toc-section" id="%E8%8B%A5%E5%AE%AE%E5%85%AB%E5%B9%A1%E5%AE%AE"></span>若宮八幡宮<span class="ez-toc-section-end"></span></h2>「.entry-content」のdivタグで囲まれた記事内のh2タグが使用された見出しを取得します。記事内はで囲まれています。
画像では目次にマーカーを引いていますが、これは見出しタグから作られるもので取得する内容がわかりやすいということで引いています。実際にはその下の「若宮八幡宮」と書かれた見出し部分を取得することになります。

記事の最下部には投稿日があるのでこれも取得します。
<div class="entry-footer">
<div class="footer-post-meta">
<div class="post-date">2021年3月24日 投稿</div>
<div style="font-size: 90%;">タグ:<a href="https://yamashina.iehohs.com/tag/zuishinin/" rel="tag">随心院</a></div>
</div>
</div>投稿日は.post-dateというdivタグで囲まれています。

それらを
- 投稿日
- 記事タイトル
- URL
- 見出しの一覧
の順に並べたCSVファイルにします。
プログラミング
モジュールの準備
今回のプログラムを動かすためには3つのモジュールがインストールされている必要があります。
Windows Power Shellで下記のコマンドを入れます。
# Requestsのインストール
pip install -U requests==2.24.0
# Beautiful Soup4のインストール
pip install -U beautifulsoup4==4.9.1
# HTML5対応のパーサーのインストール
pip install heml5libRequestsはURLを指定してGETリクエスト、Beautiful SoupはHTMLからのデータ抽出ができます。
また、Beautiful Soupで使用するHTML5対応のパーサーもインストールします。
Python
import requests, time, csv
from bs4 import BeautifulSoup
# 最初に読み込むURL
target_url = 'https://yamashina.iehohs.com/'
html = requests.get(target_url).text
soup = BeautifulSoup(html, 'html5lib')
res = []
# 1つ目のentry-list内にあるh4を取得
div = soup.select('.entry-list')[0]
h4_list = div.find_all('h4')
# すべてのh4を走査
for h4 in h4_list:
title = h4.text # 記事タイトル
url = h4.find('a').get('href') # リンク先のURL
# 記事内に入りh2を取得
html2 = requests.get(url).text
soup2 = BeautifulSoup(html2, 'html5lib')
div2 = soup2.select('.entry-content')[0]
h2_list = div2.find_all('h2')
h2_str = ""
# h2を「、」で繋ぐ
for h2 in h2_list:
h2_str = h2_str + h2.text + "、"
# 投稿日を取得
date = soup2.select('.post-date')[0].text
# 配列に格納
res.append([date, title, url, h2_str])
# 負荷軽減のため1秒遅延させる
time.sleep(1)
# CSV出力
with open('list.csv', 'wt', encoding='sjis', newline="") as fp:
csv.writer(fp).writerows(res)

コメント