

前回はPythonを使ってウェブページ上のテキスト情報を取得するスクレイピングを行いました。
今回はこれを少し応用してウェブページ上に表示されている画像を一括でダウンロードしてしまいます。
リンク
前回と同様に『シゴトがはかどる Python自動処理の教科書』を参考にしています。といっても画像をダウンロードする箇所ぐらいで、あとは前回のスクレイピングの応用で済みました。
プログラムの内容
こちらがサンプルデータです。
対象となるページは僕が作ったサイトですが、今は閉鎖しちゃったのでスクショだけでイメージしてください。

このように各史跡の案内ページの一覧があり、それぞれサムネイル画像表示されています。これらの画像をダウンロードしていきます。
<div class="entry-content">
<div class="shiseki-card">
<div class="shiseki-thumbnail">
<a href="https://yamashina.iehohs.com/shiseki/bishamon/"><img width="640" height="424" src="https://yamashina.iehohs.com/wp-content/uploads/bishamon-640x424.jpg" class="attachment-medium size-medium wp-post-image" alt="毘沙門堂" loading="lazy" srcset="https://yamashina.iehohs.com/wp-content/uploads/bishamon-640x424.jpg 640w, https://yamashina.iehohs.com/wp-content/uploads/bishamon-1280x848.jpg 1280w, https://yamashina.iehohs.com/wp-content/uploads/bishamon-768x509.jpg 768w, https://yamashina.iehohs.com/wp-content/uploads/bishamon-1536x1018.jpg 1536w, https://yamashina.iehohs.com/wp-content/uploads/bishamon.jpg 1920w" sizes="(max-width: 640px) 100vw, 640px" /></a>
</div>
<div class="shiseki-name">
<h3><a href="https://yamashina.iehohs.com/shiseki/bishamon/" title="毘沙門堂">毘沙門堂</a></h3>
</div>
<div class="shiseki-address">
京都市山科区安朱稲荷山町18
</div>
<div class="shiseki-station">
最寄駅:山科駅
</div>
</div>HTMLの一部抜粋です。この一覧は.entry-contentというdivで囲まれており、画像はその中の.shiseki-thumbnailというdivに囲まれています。
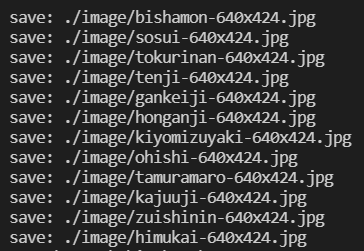
プログラムを実行すると同じディレクトリにimageというフォルダを作成し、その中に画像データをかダウンロードしていきます。
この時のファイル名は画像URLのディレクトリ部分を取り除いたものになります。
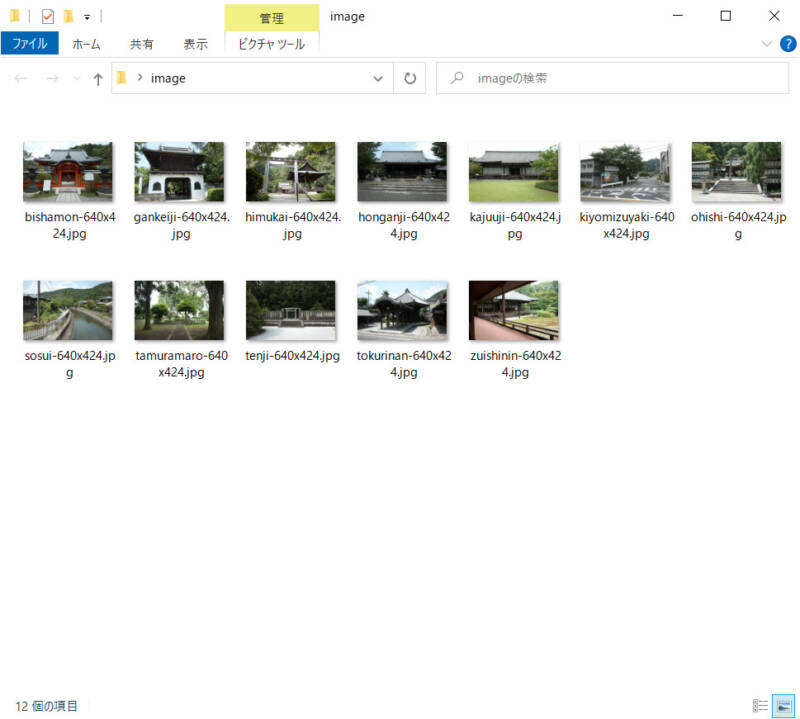
こんな感じです(サムネイルに横幅640pxって大きすぎな気が)
プログラミング
モジュールの準備
前回と同様にモジュールの準備が必要です。PowerShellで下記のコマンドを入力します。
既にインストールしていたら飛ばしてOKです。
# Requestsのインストール
pip install -U requests==2.24.0
# Beautiful Soup4のインストール
pip install -U beautifulsoup4==4.9.1
# HTML5対応のパーサーのインストール
pip install heml5libPython
import requests, os, time
from bs4 import BeautifulSoup
# 対象ページのURL
target_url = 'https://ymsn.iehohs.net/shiseki/'
# 画像ファイルのアップロード先URL
uploads_url = 'https://ymsn.iehohs.net/wp/wp-content/uploads/'
html = requests.get(target_url).text
soup = BeautifulSoup(html, 'html5lib')
div = soup.select('.entry-content')[0]
# サムネイル画像のクラス属性
thm_list = div.select('.shiseki-thumbnail')
# 保存先のフォルダを指定
save_dir = './image'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
# 各サムネイル画像を走査
for thm in thm_list:
url = thm.find('img').get('src')
res = requests.get(url)
# フォルダに保存
file_name = url.replace(uploads_url, '')
save_file = save_dir + '/' + file_name
with open(save_file, 'wb') as fp:
fp.write(res.content)
print("save:", save_file)
time.sleep(1,

コメント