
Accessの勉強をしようと思っているのですが、ただテキストを進めるだけではモチベーションが上がらないし脳があまり働きません。
プログラミングもそうですが、学習する時には自分にとって欲しいものを作るのが1番です。
何かいい題材がないかなぁと考えた結果、競馬の血統データベースを作ろうと思います。
過去の重賞レースで3着以内に入った馬の血統を集めて、レースやコースごとに傾向がないか分析するツールを作ります。
まずは各レースの結果と勝ち馬などの血統をまとめたデータをGASを使ったWebスクレイピングで集めます。
netkeibaからレース結果を取得
今回使用するのはnetkeibaです。
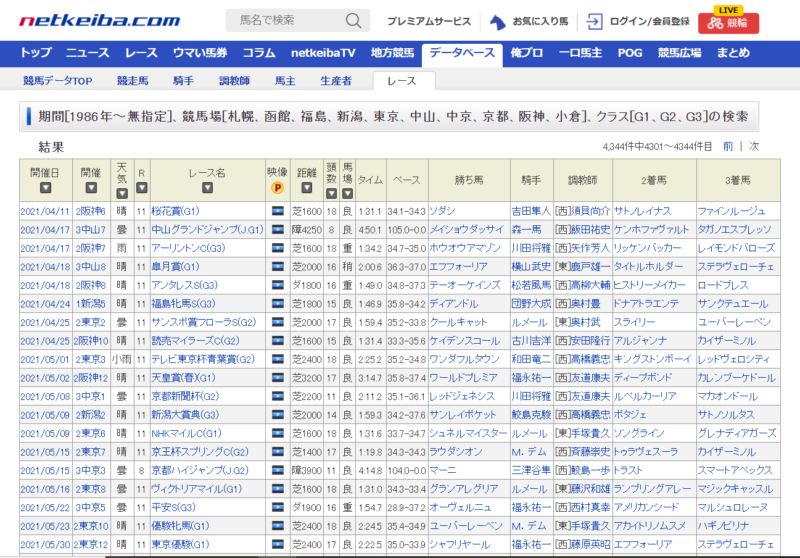
データベース検索から1986年以降のJRA競馬場で行われたG1、G2、G3のレースに絞り込んで検索します。いつの分から取得するかは迷いましたが、グレード制が導入された年からということで1986年にしました。
検索結果の一覧画面に概要が表示されます。ここにコースの情報や3着以内の馬名が表示されますので、これだけの情報で十分です。
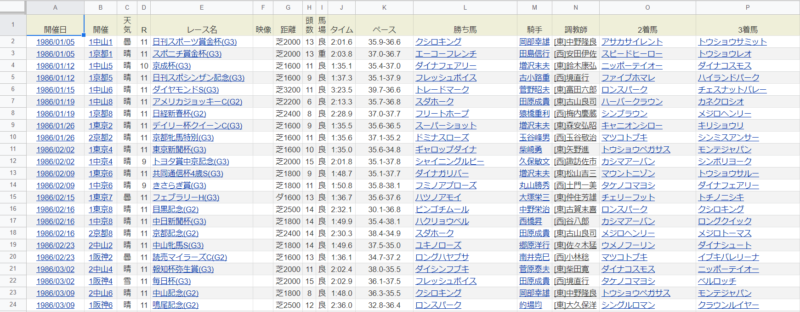
スマートではありませんが、表示件数を100件にしてテーブルをコピペしてスプレッドシートに貼り付けというのを全ページやっていきます。
重複する馬を削除
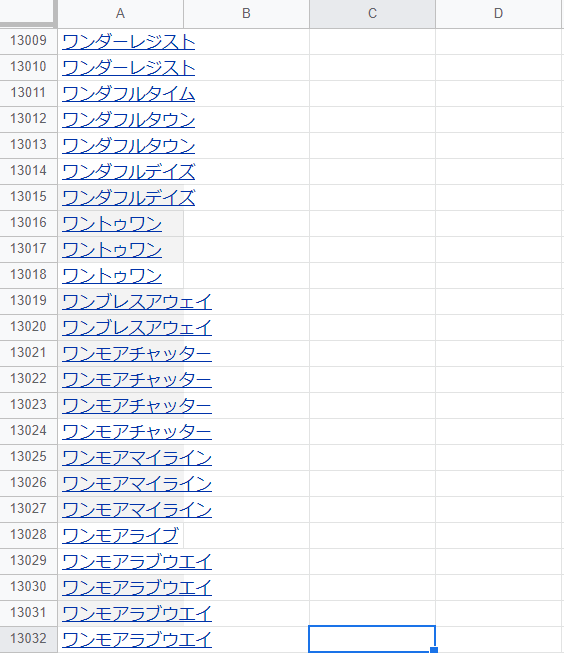
別シートに1~3着の馬を1列に並べます。13032行もありますが、馬名でソートしてみると結構重複しています。
そこで重複する馬を削除します。GASを使います。
GAS
function rowdelete(){
const sheet = SpreadsheetApp.getActiveSheet();
var lastrow = sheet.getLastRow();
for (i=lastrow;i>1;i--){
var j = i - 1;
var a = sheet.getRange("A"+i).getValue();
var b = sheet.getRange("A"+j).getValue();
if(a==b){
sheet.deleteRows(i);
Logger.log(a);
}
}
}最終行から順番に上のセルと同じ名前だったら行削除をします。
上から順番にやる場合、行削除をする際にカウンタとなる変数のカウントを止める必要がありますし、最終行の値が変わったりと面倒なことが多いので下から処理を行います。
たいしたことをしていないのですが、1行を処理するだけでも結構時間がかかります。GASは6分で処理を終えないと中止してしまうので何回も再実行するハメに。
たぶんExcelに移してVBAでやる方が速いですね。
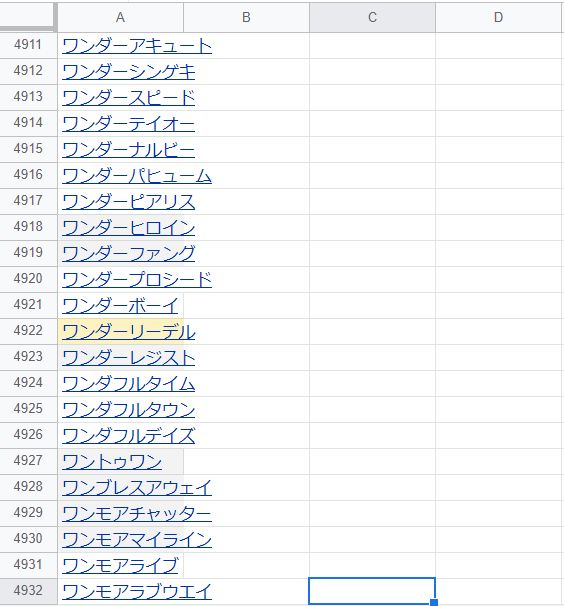
各馬の血統データを取得する
各馬のページにある血統表から父・父父・母父を取得したいところ。
最初に取得した一覧では各馬の名前にハイパーリンクが設定されており各馬のページに飛ぶことができます。
これを一つひとつ開いて入力……っていうのをしていってもいいのですが、5,000件近くあるのでやってられません。
そういうわけでスクレイピングの出番です。
URLを取得する
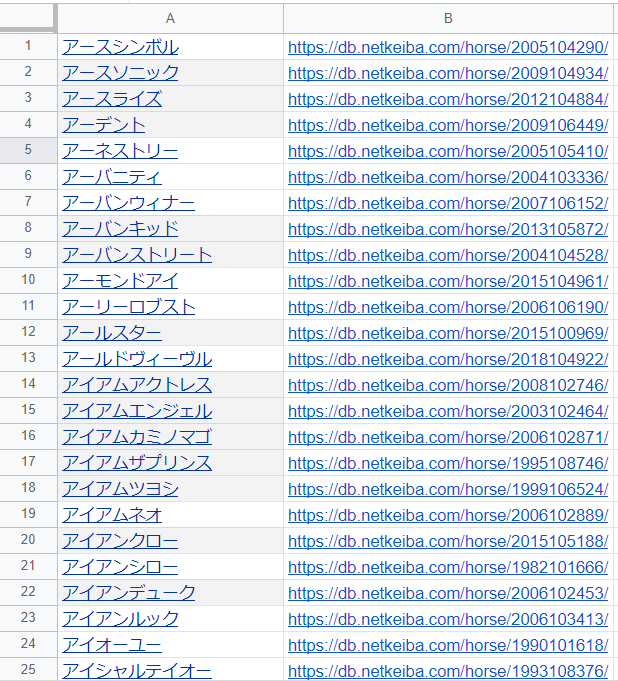
まずはスクレイピングの準備から。各ページにアクセスするためにはURLが必要です。
そういうわけで各ハイパーリンクからURLだけを取り出します。
GAS
function getlinks() {
const sheet = SpreadsheetApp.getActiveSheet();
var lastrow = sheet.getLastRow();
for (i=1;i<lastrow+1;i++){
var vals = sheet.getRange("A"+i).getRichTextValue();
var url = vals.getLinkUrl();
sheet.getRange("B"+i).setValue(url);
}
}getRichTextValue関数を使って取得したオブジェクトに対してgetLinkUrl関数を使うと、ハイパーリンクに設定されているURLを取り出すことができます。
取り出したURLはB列に入力します。
スクレイピング
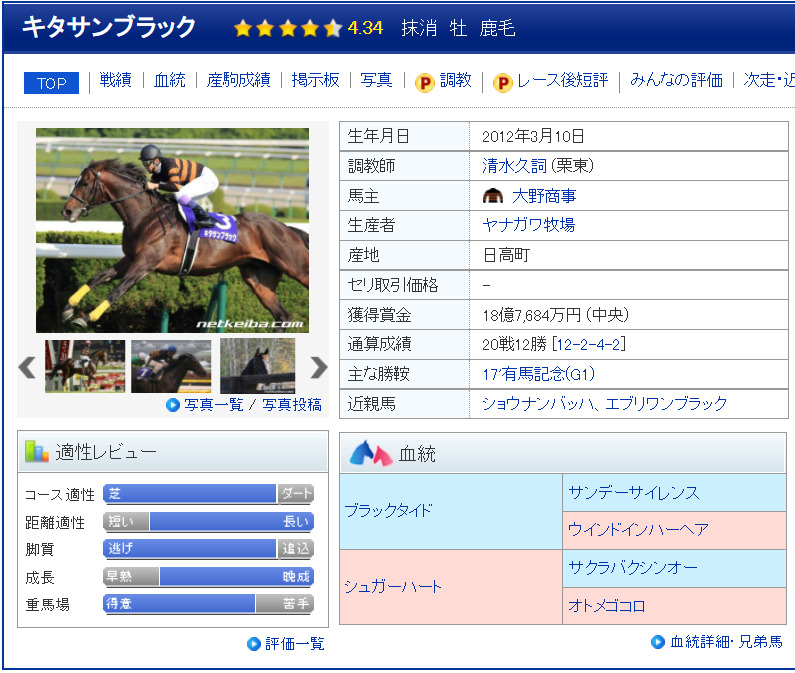
血統表から父・父父・母父を取得します。
このキタサンブラックの場合は、父がブラックタイド、父父がサンデーサイレンス、母父がサクラバクシンオーです。
血統表部分のHTMLはこのようになっています。
<table cellpadding="0" cellspacing="0" summary="キタサンブラックの血統表" class="blood_table">
<tr>
<td rowspan="2" class="b_ml">
<a href="/horse/ped/2001103312/" title="ブラックタイド">ブラックタイド</a>
</td>
<td class="b_ml">
<a href="/horse/ped/000a00033a/">サンデーサイレンス</a>
</td>
</tr>
<tr>
<td class="b_fml">
<a href="/horse/ped/000a0003a2/">ウインドインハーヘア</a>
</td>
</tr>
<tr>
<td rowspan="2" class="b_fml">
<a href="/horse/ped/2005106935/">シュガーハート</a>
</td>
<td class="b_ml">
<a href="/horse/ped/1989108341/">サクラバクシンオー</a>
</td>
</tr>
<tr>
<td class="b_fml">
<a href="/horse/ped/1990104600/">オトメゴコロ</a>
</td>
</tr>
</table>スクレイピングで頭を使うのはどうすれば余計な情報を取り除いて、必要な情報だけを取り出せるか。
そのためにはタグや付与されたクラス名などで差別化する必要があります。
.blood_tableというクラス名はこの血統表でしか使われていないので、これで血統表の中身は簡単に取得できますね。
各馬の名前に共通していて、他とは異なる点を探すと、「”>」と「</a>」に囲まれている範囲と定義づけれますね。
そうして取得した6つの馬の名前の内、1・2・5つ目が今回取得したい文字列です。
GAS
function scraping() {
const sheet = SpreadsheetApp.getActiveSheet();
var lastrow = sheet.getLastRow();
for (i=3762;i<lastrow+1;i++){
var url = sheet.getRange("B"+i).getValue();
var content = UrlFetchApp.fetch(url).getContentText("euc-jp");
var $ = Cheerio.load(content,{
decodeEntities:false
});
var $bloodtable = $('.blood_table');
$bloodtable.each(function(index, element) {
var horsename = $(element).html().match(/">.*?<\/a>/g).toString();
horsename = horsename.split(',');
var father = horsename[0].replace('">','').replace('</a>','');
var ffather = horsename[1].replace('">','').replace('</a>','');
var mfather = horsename[4].replace('">','').replace('</a>','');
sheet.getRange("C"+i).setValue(father);
sheet.getRange("D"+i).setValue(ffather);
sheet.getRange("E"+i).setValue(mfather);
Utilities.sleep(1000);
});
}
}match関数で「”>」と「</a>」に囲まれた範囲を文字列として取得します。
match関数の中で始まりと終わりを表すのに「/」が使われているので、探す文字列の中で「/」を使用する場合は「\」をつけてエスケープさせる必要があります。
こうして取得すると「,」で区切られるのでsplit関数を使って配列にします。配列のインデックスは0から始まるので、0が父、1が父父、4が母父となります。
このままでは「”>」と「</a>」も一緒にくっついた状態なのでreplace関数で消します。
これで馬名を取得できたので、あとはC列に父、D列に父父、E列に母父を入力します。
今回の注意点は、netkeibaのサイトがeuc-jpの文字コードを使用していたため、getContentText関数の引数に「euc-jp」と入れています。
あとスクレイピングはサーバーに負荷がかかるため、処理の合間にひと呼吸休むタイミングを入れてやる必要があります。Utilities.sleep関数を使って今回は1000ミリ秒 (1秒) 休むようにしています。

そんな感じで大量のデータを取得することができました。
これを手作業でやってたら大変どころの騒ぎではありません。
次はこのデータを加工してAccessに取り込んでいきます。


コメント