
OCRって特別な機材を入れないとできないものかと思っていましたが、GASを使えばGoogleドライブ上の画像やPDFデータからテキストを抽出できるようです。しかも無料で。
そういうわけでGASでのOCR方法です。Wordから作成したPDF、WebページをスクリーンショットしたPNG、紙に手書きで書いたものをスマホのカメラで撮ったJPEGの3パターンでOCRをやってみます。
プログラムの内容
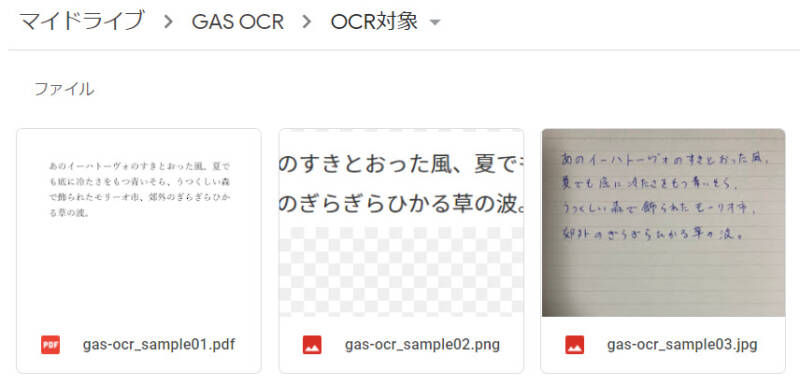
今回OCR対象のファイルたちです。
まずはWordで作成した文書をCube PDFでPDF化したものです。PDFですがテキストを選択してコピペとかできるのでこれは確実にいけそうですね。
2つ目はWebページをスクリーンショットしたPNG画像。このブログの投稿ページに入力してプレビューし、それをSnipping Toolで撮影したものです。こちらは完全に画像データ。

3つ目はルーズリーフに僕がボールペンで手書きで書いたものを、iPhoneで適当に撮影したもの。手の影ができていますが、それ以上に字が汚いのでこれは期待が薄い。「うつくしい」が「うっくしい」に見えたり、「ぎらぎら」が絶妙に読みにくい。

これらのファイルをGoogleドライブで作成したフォルダに入れます。
OCRの結果
OCRを実行すると、ドキュメントのファイルが作成されます。
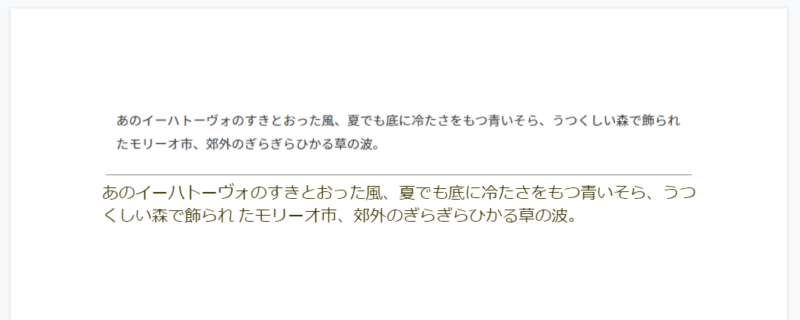
まずは1つ目のPDF。余裕でテキストを取得できていますね。おまけにページサイズも反映されています。

2つ目のPNGファイル。画像データの場合は、先に画像データを表示したあとにテキストデータが表示される仕様のようです。こちらも取得できていますね。
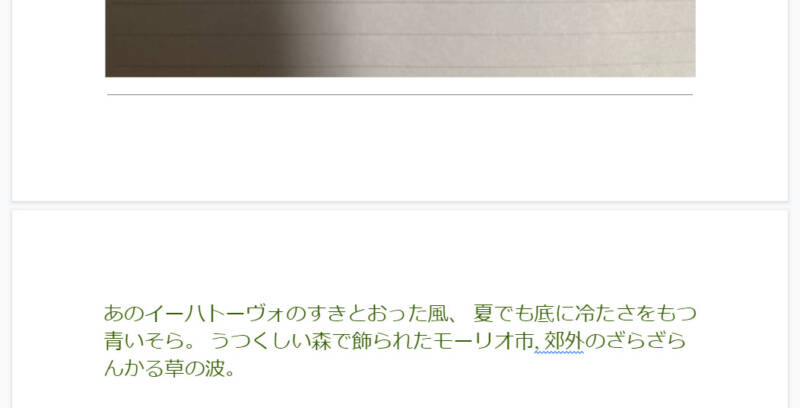
いよいよ3つ目の紙に手書き&スマホ撮影。残念ながら鬼門と思っていた「ぎらぎらひかる」が案の定「ざらざらんかる」になってしまいました。
ただ、それ以外は間違いなく取得できており、かなり精度が高いことがわかりました。
プログラミング (GAS)
function myFunction() {
const ocrFolderID = 'OCR対象フォルダ';
let files = DriveApp.getFolderById(ocrFolderID).getFiles(); // OCR対象フォルダに入っているファイルを取得
let option = {
'ocr': true, // OCRを行うかの設定
'ocrLanguage': 'ja',// OCRを行う言語の設定
}
while(files.hasNext()){ // 取得したファイルを1件ずつ処理
let file = files.next(); // ファイル単体を取得
subject = file.getName(); // ファイル名を取得
let resource = {
title: subject
};
let image = Drive.Files.copy(resource, file.getId(), option); // 指定したファイルをコピー
let text = DocumentApp.openById(image.id).getBody().getText(); // コピー先ファイルのOCRのデータを取得
console.log(text);
// OCR後のデータ削除を行う場合はコメントアウトを外す
// Drive.Files.remove(image.id);
}
}
2行目のocrFolderIDには、Googleドライブでフォルダを開いた時に表示されるURL「https://drive.google.com/drive/u/0/folders/****************」の*の部分を入力します。
このフォルダ内にあるファイルに対してOCRを実施し、作成されるドキュメントファイルも同じフォルダに入れます。
テキストを取得できればこのドキュメントファイルは不要ということであれば、最後の「Drive.Files.remove」のコメントアウトを外してください。
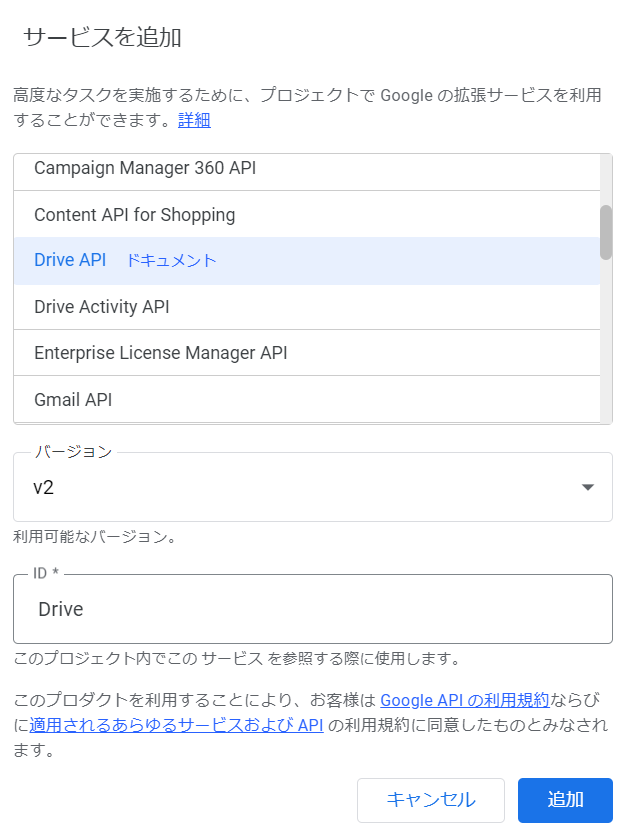
Drive APIの有効
このOCRを実行するにはDrive APIを有効にする必要があります。
Apps Scriptのメニューより、サービスの+マークを推してDrive APIを追加すればOK。


コメント